
KMP算法详解
更多
【算法4】dijkstra的双栈算术求值算法
更多
Redis基础理论知识详解
学了一段时间的redis,觉得以前对Redis的了解太过浅薄了, 现在内心有种强烈的冲动想要把最近学到的知识和我对Redis的理解给写出来。 Redis是什么 Redis是一个基于键值对的NoSQL数据库,与很多键值对数据库不同,Redis 提供了丰富的 值数据存储结构,包括 string、hash、list、set、zset(有序集合)等。 为什么要使用Redis  随着互联网用户的不断增加,早在90年代单靠一个MySQL就能支撑起整个网站的数据服务已经不复存在了,..
更多
【算法】排序算法系列详解---归并排序
排序算法 想要理解排序算法,我们先得了解什么是分而治之思想,一种著名的递归式问题解决方案。很多算法中都用到了这种思想。 D&C 分而治之 比方说我们有这样一块168 * 64的地皮,我们需要在尽可能大的情况下去均匀的分成正方形,求该正方形的边长。 所谓的分而治之就是把问题缩小化,大问题分成中等问题,中等问题分解成小问题来解决。 这道题我们可以通过不断的找正方形来慢慢分割出小问题来。先在这块地中划出64*64的正方形,那么剩余的地皮为40 * 64,再进行分割,如此往复… 最终会得到一个8*8的方块,这个就是一个典型的分而治之思想。 归并排序 归并排序有两种,自顶向下和自底向上。 自顶向下算法思路 将数组拆分成两部分,先处理左边再处理右边,通过递归的方式对两边进行拆分,一直拆分到只有一个元素为..
更多
浅谈Python中类方法、实例方法和静态方法的区别
更多
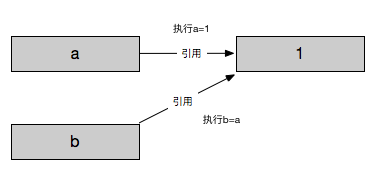
浅谈python中的引用、拷贝、指针与C++的区别
最近在学C++,在刷题的时候遇到了关于引用、指针的问题,重温相关知识后发现C++中的引用于python中引用有很大的区别,我想这就是C++效率远高于python的原因之一。通过两篇文章想梳理下python与C++在引用上的区别以及C++中引用和指针的区别。 Python的引用 在python中引用就是引用赋值,等同于浅拷贝,可以看一个例子: In [13]: a = 1 In [14]: b = a In [15]: id(a) Out[15]: 4553065616 In [16]: id(b) Out[16]: 4553065616 In [20]: b is a Out[20]: True In [21]: b == a Out[21]: True 上面代码中先初始化了一个值为1,名字..
更多
如何理解Python的接口类、抽象类、多态和鸭子类型
抽象类 抽象类是一个特殊的类,为了在团队开发中能够规范化代码而延伸出来的知识,源于java,这种类它只能被继承而不能被实例化。这也说明了该类中的所有函数以及属性都将用来被继承。 为什么要使用抽象类 规范代码: 它的子类必须实现抽象类中的所有函数 前面有提到有一点就是为了规范代码,在团队协作中很经常会遇到多个人开发同一个模块的情况,如果因为函数命名问题导致两个子类中的方法不同。为了避免这种问题才出现了抽象类这种概念。 易于维护: 还有另外个原因是为了减少代码的重复量和易于维护。比方说我们有多个汽车产品,不同的汽车有不同的功能。有的有自动驾驶,有的有全景天窗,但是只要是汽车都会有行驶,左转右转等基本功能,这些基本功能我们就可以放在抽象类中。 from abc import ABCMeta,abst..
更多python迭代器、生成器看完这篇你就懂了
生成器是python中非常有用特性,而且十分特殊,特殊到以前学过的语言都没有这种功能,身边的一些学其他语言的开发朋友也都不清楚生成器是什么。 所以在这篇文章中将尽可能详细的解释下生成器是什么,迭代器是什么 可迭代对象 在说生成器之前我们必须得提可迭代对象。可迭代对象是什么,顾名思义迭代器就是支持迭代操作的对象。在python3如列表,字典,字符串都是可迭代对象,简单来说就是任何实现了__next__方法的容器都是可迭代对象,而可迭代对象可以转换成迭代器。 迭代器甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。 看了下面的代码应该会清楚很多 In [7]: a = [1,2,3] In [8]: b = iter(a) In [9]: a Out[9]: [1..
更多
Python爬虫之Scrapy-框架原理
Scrapy介绍 scrapy框架包含以下几个部分 Scrapy Engine 引擎 Spiders 爬虫 Scheduler 调度器 Downloader 下载器 Item Pipeline 项目管道 Downloader Middlewares 下载器中间件 Spider Middlewares 爬虫中间件 框架中有那么多部分组成,那每个部件都是用来做什么的?查阅官方文档后我有了以下结论 Scrapy Engine引擎 它是负责整个框架中信号,数据等传递功能。相当于是军队中的主公,任何事情必须经过它的手由它来决定这件事情由谁来负责。 Spiders爬虫 是这个框架中的军师,负责处理所有的Response,返回封装在Item中的数据包。如果有更深层的URL,它将返回给Scrapy Engine,再次..
更多Python爬虫之Scrapy-安装及入门
简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 ###环境需求 Python2.7 或者Python3.5以上 安装 在安装前需要确定当前的Python是什么版本,否则会出现环境变量与当前版本不匹配的情况导致找不到文件:command not found pip install scrapy 如果安装太慢,就把镜像源改为国内: pip install -i https://pypi.douban.com/simple scrapy 安装过程中你会发现,scrapy有大量的依赖库: twisted 基于事件驱动和异步的网络框架 lxml python的一个解析库,支持HTML和XML的解析,支持XPath解..
更多