
打家劫舍三部曲
更多54. 螺旋矩阵
更多143. 重排链表
更多138. 复制带随机指针的链表
更多718. 最长重复子数组
更多209. 长度最小的子数组
更多543. 二叉树的直径
更多101. 对称二叉树
更多112. 路径总和
更多204. 计数质数
更多496. 下一个更大元素 I
更多31. 下一个排列
更多56. 合并区间
更多33. 搜索旋转排序数组
更多88. 合并两个有序数组
更多121. 买卖股票的最佳时机
更多53. 最大子序和
更多iOS常见面试题
iOS常见面试题
更多15. 三数之和
更多560. 和为K的子数组
更多739. 每日温度
更多678. 有效的括号字符串
更多6. Z 字形变换
更多17. 电话号码的字母组合
更多680. 验证回文字符串 Ⅱ
更多71. 简化路径
更多KMP算法详解
更多
556. 下一个更大元素 III
更多
443. 压缩字符串
更多91. 解码方法
更多22. 括号生成
更多43. 字符串相乘
更多227. 基本计算器 II
更多468. 验证IP地址
更多14. 最长公共前缀
更多93. 复原 IP 地址
更多8. 字符串转换整数 (atoi)
更多151. 翻转字符串里的单词
更多415. 字符串相加
更多3. 无重复字符的最长子串
更多82. 删除排序链表中的重复元素 II
更多148. 排序链表
更多92. 反转链表 II
更多142. 环形链表 II
更多150. 逆波兰表达式求值
更多【算法4】dijkstra的双栈算术求值算法
更多503.下一个更大元素2
更多二叉树的前序、中序、后序算法
更多2. 两数相加
更多剑指 Offer 48. 最长不含重复字符的子字符串
更多706. 设计哈希映射
更多剑指 Offer 50. 第一个只出现一次的字符
更多剑指 Offer 62. 圆圈中最后剩下的数字
更多剑指 Offer 56 - I. 数组中数字出现的次数
更多剑指 Offer 35. 复杂链表的复制
更多剑指 Offer 57 - II. 和为s的连续正数序列
更多剑指 Offer 03. 数组中重复的数字
更多面试题 17.16. 按摩师
更多剑指-Offer-32-I-从上到下打印二叉树
更多剑指-Offer-25-合并两个排序的链表
更多剑指-Offer-09-用两个栈实现队列
更多面试题 03.04. 化栈为队
更多559-N-叉树的最大深度
更多剑指 Offer 06. 从尾到头打印链表
更多129. 求根到叶子节点数字之和
更多81. 搜索旋转排序数组 II
更多
Redis基础理论知识详解
学了一段时间的redis,觉得以前对Redis的了解太过浅薄了, 现在内心有种强烈的冲动想要把最近学到的知识和我对Redis的理解给写出来。 Redis是什么 Redis是一个基于键值对的NoSQL数据库,与很多键值对数据库不同,Redis 提供了丰富的 值数据存储结构,包括 string、hash、list、set、zset(有序集合)等。 为什么要使用Redis  随着互联网用户的不断增加,早在90年代单靠一个MySQL就能支撑起整个网站的数据服务已经不复存在了,..
更多面试题 02.02. 返回倒数第 k 个节点
更多剑指 Offer 39. 数组中出现次数超过一半的数字
更多20. 有效的括号
更多104. 二叉树的最大深度
更多面试题 01.06. 字符串压缩
更多19. 删除链表的倒数第 N 个结点
更多349. 两个数组的交集
更多160. 相交链表
更多268. 丢失的数字
更多141. 环形链表
更多704. 二分查找
更多1436. 旅行终点站
更多234. 回文链表
更多237. 删除链表中的节点
更多925. 长按键入
更多145. 二叉树的后序遍历
更多144. 二叉树的前序遍历
更多1614. 括号的最大嵌套深度
更多94. 二叉树的中序遍历
更多206. 反转链表
更多102. 二叉树的层序遍历
更多剑指 Offer 68 - II. 二叉树的最近公共祖先
更多189. 旋转数组
更多26. 删除排序数组中的重复项
更多剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
更多面试题-04-03-特定深度节点链表
更多剑指 Offer 58 - II. 左旋转字符串
更多剑指 Offer 54. 二叉搜索树的第k大节点
更多
【算法】排序算法系列详解---归并排序
排序算法 想要理解排序算法,我们先得了解什么是分而治之思想,一种著名的递归式问题解决方案。很多算法中都用到了这种思想。 D&C 分而治之 比方说我们有这样一块168 * 64的地皮,我们需要在尽可能大的情况下去均匀的分成正方形,求该正方形的边长。 所谓的分而治之就是把问题缩小化,大问题分成中等问题,中等问题分解成小问题来解决。 这道题我们可以通过不断的找正方形来慢慢分割出小问题来。先在这块地中划出64*64的正方形,那么剩余的地皮为40 * 64,再进行分割,如此往复… 最终会得到一个8*8的方块,这个就是一个典型的分而治之思想。 归并排序 归并排序有两种,自顶向下和自底向上。 自顶向下算法思路 将数组拆分成两部分,先处理左边再处理右边,通过递归的方式对两边进行拆分,一直拆分到只有一个元素为..
更多122-买卖股票的最佳时机-II
更多657. 机器人能否返回原点
更多浅谈Redis的持久化:RDB与AOF
Redis数据持久化 Redis可不单单是一个缓存型数据库,如果出现Redis服务出现问题导致关闭或者人为的操作导致停止运行,那么所有的数据都将丢失。 为此Redis推出了数据持久化的方案,Redis推出了两种方案:RDB与AOF RDB快照 什么是RDB快照,RDB快照有点类似于传统数据库的db文件。指的是将Redis中的数据以二进制格式存储在RDB文件中,因为是在磁盘上进行的操作,所以每次写入数据都是IO操作。为了减少磁盘的负担,Redis支持修改RDB文件的写入时间间隔: save <seconds> <changes>表示在seconds秒内,至少有changes次变化,就会自动触发bgsave命令 save 900 1 当时间到900秒时,如果至少有1个key发生变化..
更多
自己动手实现简易版sqlite(一).md
前言 在动手学习这块知识之前本身是抱着想了解数据库是如何实现的目的,但越往后越觉得数据库这个项目真的是复杂,但是也十分有趣。所以特地在此记录下我这些天来对sqlite的理解。 本篇文章是以简易版的sqlite(后面简称sqlite)为基础写出来的原理剖析,还有很多sqlite的基本功能还未涉及到,之后我会逐步添加上去。 框架结构 本项目用c语言实现 测试工具为rspec 本sqlite的基本架构分为: 核心层 接口 SQL命令处理程序 分词器(Tokenizer) 分析器(Parser) 代码生成器(Code Generator) 虚拟机(后台) B树 (B-Tree) 页面调度程序(Pager) 操作系统接口 (OS Interface) 其他辅助类 一般我们把接口和SQL命..
更多589. N 叉树的前序遍历
更多
146. LRU 缓存机制
前言 今天在刷leetcode的时候,遇到了LRU缓存机制的问题。觉得很有意思,就准备把这道题的题解以及相关知识点记录下来。 原题是这样的 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。 获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。 写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。 结合实际场景来分析这道题的话就是我们现在有一个空间有限的缓存池,为了保证缓存不会溢出我..
更多计算机的基本组成
一、计算机系统概论 冯诺依曼计算机组成 主机(cpu+内存),外设(输入设备+输出设备+外存),总线(地址总线+数据总线+控制总线) 计算机层次结构 应用程序-高级语言-汇编语言-操作系统-指令集架构层-微代码层-硬件逻辑层 计算机性能指标 非时间指标 【字长】机器一次能处理的二进制位数 ,常见的有32位或64位 【总线宽度】数据总线一次能并行处理的最大信息位数,一般指运算器与存储器之间的数据总线的位数 【主存容量】主存的大小 【存储带宽】单位时间内与主存交换的二进制位数 B/s 时间指标 【主频f】时钟震荡的频率 Hz;【时钟周期T】时钟震荡一次的时间 t 【外频】cpu与主板之间同步的时钟频率,系统总线的工作频率;【倍频】主频与外频的倍数 =主频/外频 【CPI】clock cycles p..
更多横扫offer笔记 面向对象
不可变数据类型是永远不会被改变的。 const int i = 0; //指定变量i为不可变常量 int * j = (int *)&i; //强行将j的指针指向常变量i, &i指的是得到变量i的内存地址 * j = 1; printf("%d %d", i, *j) 最终得到0,1 因为i是常变量(不可改变的变量),所以即使指针变量j指向了i的地址之后重新赋值。这个时候内存会为常变量开辟一个新的内存地址来存储原始值0,并且在输出的时候使用的还是原来的值。 *j指的是这个指针变量所指向的值,也就是它所存储的内存地址,通过该地址找到的值 如果这个时候输出j,那么将打印出*j中存储的内存地址 在16位机器上,下面这段代码输出结果: int i = 65536; ..
更多横扫offer笔记 C++基础
基本运算 C语言中,以数字0开头的是八进制形式,以0x或0X开头的是十六进制形式,常数的后面加字母L为长整数. %hd用来输出 short int 类型,hd 是 short decimal 的简写; %d用来输出 int 类型,d 是 decimal 的简写; %ld用来输出 long int 类型,ld 是 long decimal 的简写。 浮点数:在高级语言程序设计中,对于两个浮点类型的变量x,y一般不直接使用语句if(x==y)。因为在计算机中浮点数不一定会被精确显示,特别是小数点后三位之后。所以一般我们判断两个浮点数是否相等时需要这样写:|x-y| > 0.000001 unsigned int a = 6 表示的是无符号整数 取值范围是
更多Python面试题四
Python中类方法、类实例方法、静态方法有何区别? 实例方法:类的实例化对象的方法,参数是self,指向该类的实例。通过self可以自由的调用该对象的属性和其它方法,也可以修改。 类方法:使用@classmethod装饰器的类方法,参数为cls,不同于实例方法,cls不能对类中的属性做修改 静态方法:使用@staticmethod装饰器的类方法,不接受cls和self,但是可以接受其它参数。所以它不能访问该类的属性和方法,只能访问该类中的全局变量。 参考链接 请描述抽象类和接口类的区别和联系 举个简单的例子,你需要设计一个关于汽车的类。为了便于以后的扩展,我们把汽车的基本功能放入到抽象类中去,如行驶,倒车,转弯这些方法,车灯,轮胎等属性。 突然我们开发出了一台支持自动驾驶的车,因为这个功能不是每..
更多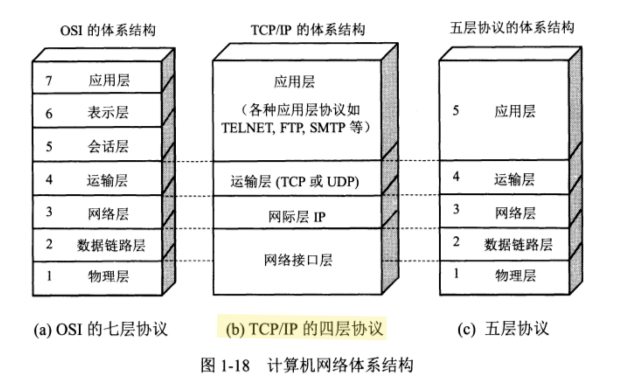
Http学习笔记
根据上野宣的《图解HTTP》整理的个人学习笔记,记录重点与配图 计算机网络体系结构 具有五层协议的体系结构 一般提到计算机网络体系结构,都指的是五层协议。七层协议虽然足够完整,但是过于复杂而且不实用。 应用层 应用层决定了向用户提供应用服务时通信的活动。 TCP/IP协议族内预存了各类通用的应用服务。比如FTP(File Transfer Protocol, 文件传输协议) 和 DNS(Domain Name System, 域名系统)服务就是其中两类。 传输层 传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。 在传输层有两个性质不同的协议,TCP(Transmission Control Protocol, 传输控制协议) 和 UDP (User Data Protocol..
更多Python面试题(二)
列出python中可变数据类型和不可变数据类型,并简述原理 不可变类型:字符串str, 数值类型int, 元组tuple In [1]: a = 3 In [2]: b = 3 In [3]: id(a) Out[3]: 4494963920 In [4]: id(b) Out[4]: 4494963920 不可变类型指的是数据不允许发生变化,如果改变变量的值就只能重新创建新的对象会重新分配内存地址,所以它的id将会有所改变。 In [5]: a = 4 In [6]: id(a) Out[6]: 4494963952 可变类型:列表list和字典dict 也就是说如果对变量进行append、 +=等操作它只会改变变量的值,不会改变内存地址。对于相同值的不同对象也会占用不同的内存地址。 In..
更多Python面试题
一行代码实现1-100之和 sum(range(100)) 如何在一个函数内部修改全局变量 In [1]: c = 0 In [3]: def change_count(): ...: global c ...: c = 1 ...: print(c) ...: In [4]: change_count() 1 In [5]: c Out[5]: 1 列出5个python标准库 os: 提供操作系统有关的函数 sys: 通常用于命令行参数 re: 正则匹配 math: 数学运算 datetime: 处理日期时间 字典如何删除键和合并两个字典 删除: del dic['key'] 合并: In [1]: dic1 = {&..
更多
浅谈Python中类方法、实例方法和静态方法的区别
更多
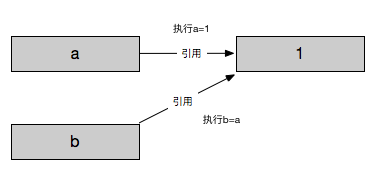
浅谈python中的引用、拷贝、指针与C++的区别
最近在学C++,在刷题的时候遇到了关于引用、指针的问题,重温相关知识后发现C++中的引用于python中引用有很大的区别,我想这就是C++效率远高于python的原因之一。通过两篇文章想梳理下python与C++在引用上的区别以及C++中引用和指针的区别。 Python的引用 在python中引用就是引用赋值,等同于浅拷贝,可以看一个例子: In [13]: a = 1 In [14]: b = a In [15]: id(a) Out[15]: 4553065616 In [16]: id(b) Out[16]: 4553065616 In [20]: b is a Out[20]: True In [21]: b == a Out[21]: True 上面代码中先初始化了一个值为1,名字..
更多
如何理解Python的接口类、抽象类、多态和鸭子类型
抽象类 抽象类是一个特殊的类,为了在团队开发中能够规范化代码而延伸出来的知识,源于java,这种类它只能被继承而不能被实例化。这也说明了该类中的所有函数以及属性都将用来被继承。 为什么要使用抽象类 规范代码: 它的子类必须实现抽象类中的所有函数 前面有提到有一点就是为了规范代码,在团队协作中很经常会遇到多个人开发同一个模块的情况,如果因为函数命名问题导致两个子类中的方法不同。为了避免这种问题才出现了抽象类这种概念。 易于维护: 还有另外个原因是为了减少代码的重复量和易于维护。比方说我们有多个汽车产品,不同的汽车有不同的功能。有的有自动驾驶,有的有全景天窗,但是只要是汽车都会有行驶,左转右转等基本功能,这些基本功能我们就可以放在抽象类中。 from abc import ABCMeta,abst..
更多python迭代器、生成器看完这篇你就懂了
生成器是python中非常有用特性,而且十分特殊,特殊到以前学过的语言都没有这种功能,身边的一些学其他语言的开发朋友也都不清楚生成器是什么。 所以在这篇文章中将尽可能详细的解释下生成器是什么,迭代器是什么 可迭代对象 在说生成器之前我们必须得提可迭代对象。可迭代对象是什么,顾名思义迭代器就是支持迭代操作的对象。在python3如列表,字典,字符串都是可迭代对象,简单来说就是任何实现了__next__方法的容器都是可迭代对象,而可迭代对象可以转换成迭代器。 迭代器甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。 看了下面的代码应该会清楚很多 In [7]: a = [1,2,3] In [8]: b = iter(a) In [9]: a Out[9]: [1..
更多
浅谈MySQL中的锁
前言 之前学习了MySQL的事务管理MySQL管理事务处理 在数据库处理高并发的时候需要涉及到事务管理和锁的机制问题这两块知识。对于锁的处理一直是一个老生常谈的话题,内容太过复杂。这次借助这篇文章分享下我对Innodb中的锁的机制的理解。 快照读与当前读 在了解锁的机制前我们得先了解快照读与当前读的区别。 一般我们常用的select * from ...也是读,共享锁那也是读,它们之间有什么区别呢?其实MySQL中的读与事务隔离级别中的读是不同的读。 在 MVCC 并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。 快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,..
更多
【MySQL必知必会】管理事务处理
什么是事务处理 事务处理是为了维护数据的完整性的技术手段,是对数据库数据安全的一种保证。它能确保成批的MySQL语句要么完全执行要么完全不执行,不会存在执行部分语句而造成该处理的数据没有被处理导致数据的错乱。 举例来说:公司某位员工离职了,除了要删除职员表中的数据还需要删除财务数据表中的相关数据以及其他业务上的数据,客户关系数据等。这些操作都需要全部一起执行,否则会造成很严重的问题。 ACID 事务是DBMS的执行单位。它由有限个数据库操作语句组成。但不是任意的数据库操作序列都能成为事务。一般来说,事务是必须满足4个条件(ACID) 原子性(Atomicity) 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。 一致性(Consistency) 一致性是指事务必须使数据库从一个一致的状态变到另..
更多
算法图解之广度优先搜索
简介 广度优先搜索算法(Breathed First Search)是一种搜索算法。原理就是从树的根节点开始去遍历所有节点,从而找出最短路径。 使用范围 可以用来走迷宫,在游戏领域中可以用来做自动寻路功能 可以用来编写跳棋AI,计算多少步能获胜 也可以用来根据自己的人际关系网络查找到关系最近的医生 图 图由节点和边组成。一个节点可能与众多节点直接相连 图用于模拟不同的东西是如何相连的。 类似这样模拟了欠债关系的就是图 在遇到能用广度优先搜索算法解决问题时,我们可以先借助图来建立问题模型,然后再通过算法去解决问题。 图只是用来模拟问题模型,并不是最终答案 树形结构也是一种图,与其他图不同的是它不会往后指。 也就是说遇到问题后,我们可以通过图把问题的关键点放在节点上。用散列表把这些点按照图的结构存储起..
更多
【MySQL】浅谈MySQL的LOAD DATA
前言 好久没碰MySQL了,这次碰巧在研究superset的时候需要将一份csv格式的数据文件导入到数据库中。正好借此机会可以重温下MySQL。 数据来源 网盘密码 : g5xa 开发环境 Mac OS 10.13 MySQL 8.0 准备工作 在开始之前需要对源数据做一次清洗: 去除”,“等影响数据导入的符号 去除第一行索引值,因为它不是数据 如果需要咋数据库中加上id,那么为了对应在源数据中也要加上,excel中加上id还是很方便的。 把数据转为utf-8格式的csv文件 在这之前先简单阅读下官方文档:MySQL Documentation 可以很方便的找到LOAD DATA的表达式: LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] ..
更多【MySQL必知必会】使用触发器
触发器 当某个表发生更改时需要MySQL自动处理事件就是触发器。MySQL只会响应以下语句从而自动执行一条MySQL语句: DELETE INSERT UPDATE 创建触发器 创建触发器时,需要注意一些细节: 唯一的触发器名 触发器关联的表 触发器应该响应的活动(DELETE,INSERT,UPDATE) 触发器何时执行(处理之前或之后) 在MySQL5中同一数据库中的两个表可以用同一个名字,但是同一个表中的触发器名字必须唯一。但是在DBMS数据库中触发器名只能唯一。 可以用CREATE TRIGGER语句创建触发器。 CREATE TRIGGER test_tt AFTER DELETE ON `test` FOR EACH ROW BEGIN DECLARE s VARCHAR(20)..
更多【MySQL必知必会】使用游标
游标 由于MySQL检索返回的是一组成为结果集的行,可能是零行也可能是多行,但是之前学到的并没有能一行一行处理的方式。而有时候需要需要在检索出来的行中前进、后退一行或多行,这个时候需要使用游标。 游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览过更改。 游标在MySQL中只能用于存储过程或者函数 使用游标的流程 在能够使用游标前,必须声明它。为了定义要使用的SELECT语句。 声明游标后需要打开游标。这个过程用SELECT语句把数据实际检索出来。 对于填有数据的游标,根据需要检索出各行。 结束游标需要关闭它 打开和关闭游标 打开:OPEN CURSOR 关闭: CLOSE CURSOR CURSOR指的是先前定义的游标名 如一个完整的打开关闭过程: CREATE PROCED..
更多【MySQL必知必会】使用存储过程
存储过程 存储过程简单来说就是为以后的使用而保存的一条或多条MySQL语句集合。这里可以理解为在实际项目中,可能会遇到不同逻辑的MySQL,这个时候需要把这些语句集合起来,相当于是一个文件。 为什么使用存储过程 通过把处理封装在容易使用的单元中,简化复杂的操作。 由于不要求反复建立一系列处理步骤,这保证了数据的完整性。如果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都是相同的。这一点的延伸就是防止错误。需要执行的步骤越多,出错的可能性就越大。防止错误保证了数据的一致性。 简化对变动的管理。如果表名、列名或业务逻辑有变化,只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化。 提高性能。因为使用存储过程比使用比使用单独的SQL语句要快。 存在一些只能用在单个请求中的MySQL元素和特性..
更多【MySQL必知必会】使用视图
视图 以例子来说明: SELECT salaries.emp_no, dept_emp.dept_no, salary, dept_name FROM salaries, dept_emp, departments WHERE salaries.emp_no = dept_emp.emp_no AND dept_emp.dept_no = departments.dept_no AND salary = 158220; 从三张表中获取薪水为158220的员工的id,部门id,薪水和部门名称。 如果使用视图,这段语句就会变成: SELECT salaries.emp_no, dept_emp.dept_no, salary, dept_name FROM salary_for_department WHE..
更多
【MySQL必知必会】插入数据
更多
【MySQL必知必会】全文本搜索
理解全文本搜索 之前学习到了用LIKE关键字,利用通配符来匹配文本,还有通过正则表达式来匹配文本。不过这些匹配都有些缺点: 性能:通配符和正则表达式匹配通常要求MySQL尝试匹配表中所有行。如果搜索行越长匹配就越耗时。 明确控制:通配符和正则表达式很难做到精细的控制,控制在匹配过程中哪些需要匹配哪些需要不匹配,这样会影响性能无法做到优化。 智能化结果:基于通配符和正则表达式的匹配得到的结果你无法控制匹配数量,比方说匹配的关键词是#,在匹配的全文中有多个#,但是我无法控制结果中只返回一个或者n个。 而这些限制都能通过全文本搜索来解决。 使用全文本搜索 一般在建表时启用全文本搜索。 MySQL最常用的两个引擎为MyISAM和InnoDB MyISAM:支持全文索引 InnoDB:不支持全文索引 CREAT..
更多【MySQL必知必会】组合查询
组合查询的使用场景 在单个查询中从不同的表返回类似结构的数据 对单个表执行多个查询,按单个查询返回数据 创建组合查询 可以通过UNION操作符来组合多条SQL查询 查询emp_no为10010以及薪水大于150000的员工 SELECT emp_no,salary FROM salaries WHERE salary > 150000 UNION SELECT emp_no, salary FROM salaries WHERE emp_no = 10010; 输出: +--------+--------+ | emp_no | salary | +--------+--------+ | 43624 | 151115 | | 43624 | 153166 | | 43624 | 153..
更多【MySQL必知必会】创建高级联结
使用不同类型的联结 上次学到的是等值联结,也是最简单的联结。这次要学习其它三种联结:自联结,自然联结和外部联结。 自联结 id为10031的员工薪水漏发了,需要确认下这个部门的所有员工,利用自联结的方法找出该部门所有员工的emp_no。 方案一: 子查询 SELECT emp_no FROM dept_emp WHERE dept_no = (SELECT dept_no FROM dept_emp WHERE emp_no = '10031') LIMIT 10 输出: +--------+ | emp_no | +--------+ | 10001 | | 10006 | | 10008 | | 10012 | | 10014 | | 10018 | | 10021 | | 1002..
更多【MySQL必知必会】使用子查询
利用子查询进行过滤 简单来说将就是利用一条SELECT语句的返回结果用于另一条WHERE语句的WHERE子句 比方说查询薪水高于150000的员工全名。这里需要查询2张表,先分开写看下 SELECT emp_no,salary FROM salaries WHERE salary > 150000; 输出: +--------+--------+ | emp_no | salary | +--------+--------+ | 43624 | 151115 | | 43624 | 153166 | | 43624 | 153458 | | 43624 | 157821 | | 43624 | 158220 | | 46439 | 150345 | | 47978 | 151929 ..
更多【MySQL必知必会】联结表
关系表 什么是关系表,假设有一个学生表,其中包含了学生姓名,出生年月,主键id, 班级id(外键)。 同时还有另外一个表,是一个班级表,其中包含主键id,班级名称。 这样的两个表就形成了关系表,学生表可以通过外键(班级id)查询到该学员的班级名称。这样的关系表也可称为一对多关系表。 外键 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。 这样做的好处: 班级信息不重复,从而不浪费查询的时间和空间。 如果班级信息有变动,直接更新班级表即可,学生表的数据不用改动 因为数据无重复,处理起来也会更加方便 为什么要使用联结 分解数据为多个表能更有效的存储,更方便的处理,并且具有更大的可伸缩性。 但是由于数据存储在多个表中,又不想使用多重子查询这种不易阅读的写法,那可以用联结。 简单来说: ..
更多【MySQL必知必会】分组数据
创建分组 SELECT emp_no, COUNT(*) FROM salaries GROUP BY emp_no HAVING emp_no < 10020; 输出: +--------+----------+ | emp_no | COUNT(*) | +--------+----------+ | 10001 | 17 | | 10002 | 6 | | 10003 | 7 | | 10004 | 16 | | 10005 | 13 | | 10006 | 12 | | 10007 | 14 | | 10008 | 3 | | 10009 | 18 | | ..
更多【MySQL必知必会】汇总数据
汇总数据 简单来说就是对数据表的检索。观察它的最大值,最小值等 SQL聚集函数 函数 说明 AVG() 返回某列的平均值 COUNT() 返回某列的行数 MAX( ) 返回某列的最大值 MIN() 返回某列的最小值 SUM() 返回某列之和 AVG函数 AVG()函数可用来返回所有列的平均值,也可返回单个列的平均值。 SELECT AVG(salary) AS avg_salary FROM salaries; 输出: +------------+ | avg_salary | +------------+ | 63810.7448 | +------------+ 1 row in set (0.75 sec) COUNT函数 两种使用方式: 使用COUNT(*..
更多【MySQL必知必会】创建计算字段
计算字段 某些数据需要通过数据库中的其他字段结合,计算,转换等才能使用。这个时候就需要用到计算字段功能了。 其实这种处理客户端和服务端都能完成,但是服务端处理这种事情更快,一般都是由服务端来解决这种事情。 拼接字段 使用Concat()函数来拼接 mysql> SELECT Concat(last_name, first_name) -> FROM employees -> ORDER BY last_name; 输出: 发现打印结果末尾有很多空格,可以使用MySQL的RTrim()函数来删除值右侧多余的空格。 mysql> SELECT Concat(RTrim(last_name), RTrim(emp_no)) AS name_no FROM employ..
更多【MySQL必知必会】正则表达式
正则表达式介绍 正则表达式可用于查找文件,可以在文本块中找到重复的单词。解析URL,处理复杂文本等。 正则表达式与MySQL的关系 通过正则对文本串进行比较来替换LIKE。 见下面例子 基本字符匹配 从first_name这个列中找出所有包含’oo’的行 SELECT first_name FROM employees WHERE first_name REGEXP 'oo'; 该代码等同于 SELECT first_name FROM employees WHERE first_name LIKE '%oo%'; 目前看下来正则在字符长度比较短的情况下,执行效率比通配符来得低。 看下面的例子: 在salaries表中,查找salary列里匹配.0000。这个.表示匹配任意一个字符,这个是通配符%..
更多【MySQL必知必会】使用数据处理函数
函数 函数提供了对数据转换和处理的功能 上篇文章中的RTrim() 以及处理时间的TIMESTAMPDIFF()都是函数。 因为函数是当前数据库使用的引擎特有,所以如果遇到移植到其他数据库就可能会出现不支持这些函数的情况。 PS:在开发中要注意这种情况,避免在移植后出现不必要的麻烦。如果必须使用函数,写好相关注释 使用函数 大多数SQL支持以下几种类型的函数: 用于处理文本串(如删除,填充,转换大小写) 对数值进行算数操作(如返回绝对值,进行代数运算) 用于处理日期 返回DMBS使用的特殊信息(如用户登录信息,版本细节) 文本处理函数 上篇了解了RTrim是去除右边空格,LTrim是去除左边空格 接下来学习个新函数-Upper(),将文本转换成大写 mysql> SELECT first_nam..
更多
算法图解笔记(四)---哈希表
哈希表 哈希表又称为散列表,是一种key-value表结构。由哈希函数和数组组成,它的原理是通过哈希函数将传入的key值计算出索引,最后从数组中通过索引快速获取数据。 哈希表结构图 一般情况下它的时间复杂度为O(1),相比较于有序列表,它的时间复杂度为O(logn)。 哈希表与列表最大的区别在于哈希表需要通过哈希函数中的算法来将key值换算成列表的索引,并且同一个key只能指向与同一个索引,也就是说一旦某个key换算成了一个索引后任何其他key都无法换算成该索引。如果出现重复的索引就称之为哈希碰撞。 在常用的语言中,哈希表通常以字典(dict)的形式表现。 哈希函数 构造哈希函数有多种方式,比如直接寻址法、数字分析法、平方取中法、折叠法、随机数法、除留余数法。 由于哈希函数有可能会出现不同的输入值会输..
更多算法图解笔记(三)\-\--快速排序
=============================== 算法的核心思想-----分而治之(D&C) D&C的理解过程: 找出基线条件,这种条件必须尽可能简单。 不断将问题分解,直到符合基线条件。 通过下面这道题来加深对D&C的理解: 将这块长为1680m,宽640m的地均匀的分成方块,且分出的方块尽可能的大。 按照D&C的解题步骤: 基线条件: 如果长是宽的整数倍,那么就可以正好将他们分割成等分的正方形。然后通过从大到小的顺序进行筛选优先找到的肯定是最大的正方形。 按照题目中的理解就是:只需找出1680余64之间的最大公约数即可。 递归条件: 通过欧几里得算法可以得知:‘适用于这小块地的最大方块同样也适用于整块地的最大方块’。这句话正好符合了分而治之的核..
更多算法图解笔记(二) \-\-- 递归
============================= 栈 每当调用函数时,计算机会将函数调用设计的所有变量存贮到内存中。 在函数内调用函数时,内部的函数在调用完成后会返回到上一次函数并且会被踢出栈堆。未完成的函数不会被踢出栈堆。 创建递归函数时刻要记得基线条件和递归条件 一段关于栈的代码解读 def fact(x): if x==1: return 1 else: return x*fact(x-1) 代码解读:(以x=3为例) 当x=3,程序进入了else条件并且执行递归,随后创建了x=2的内存块被将其放入栈堆中。 执行x=2的函数,因为此时x不等于1所以还是进入了else条件执行递归,随后创建了x=1的内存块并将其放入栈堆中。 此时x=1则进入第一个条件返回1,该轮函数..
更多大话数据结构第二章 算法
======================= 什么是算法 算法表示决绝特定问题的求解步骤,由一个或多个操作组成。 算法的特性 输入输出、有穷性、确定性、可行性。 输入输出: 不一定有输入但必须有输出 有穷性 造成死循环的代码不是算法 确定性 算法的每一个步骤都有确定的含义,无需存在多余的步骤。 可行性 算法的每一步都必须在计算机上运行 算法的时间复杂度 公式: ±----------------------------------±----------------------------------+ | 1 | T(n) = O(f(n)) | ±----------------------------..
更多算法图解笔记(一) \-\-- 选择排序、二分查找
========================================= 二分查找 是一个在有序元素列表中的查找的算法 原理:如这个列表长度是10000,通过算法排除不满足条件的另一半来查找。 比如从100个数字中找到某个数字的索引,可以先找到50进行比较来缩小范围。如果大于50就再拿75做比较,以此类推,直到找到该数字。 这样的二分算法能从原先的暴力查找(最坏情况下)100次减少到7次。 记做公式: $$log_2 n$$ 算法运行时间 运行时间的增速:随着数据量的增加,运行时间会出现递增的情况。优秀的算法增速越少,比如二分查找和简单查找在10亿个算法的情况下,简单查找需要11天才能查找玩,而二分查找只需要32毫秒。 算法的速度指的的操作数的增速。也就是时间复杂度 数组 缺点:添加新元素如果遇..
更多大话数据结构第一章 数据结构
=========================== 所有能够被计算机程序处理和可以输入到计算机中的都可以作为数据。不单单只有数值、数值类型,MP3,图片等都是数据。 数据元素与数据项的区别 数据元素是由数据项组成的单位,如某公司中的一名程序员就是数据元素。 而数据项则是由数据元素拆分而成的最小单位,这名程序员的姓名,年龄就是数据项了。 数据对象(简称为数据) 数据对象就是性质相同的数据元素的集合。某个数据元素是程序员A,程序员A、程序员B、程序员C统称为程序员,这个程序员就是数据对象。 数据结构 是相互之间存在一种或多种特定关系的数据元素的集合。 比方说:N名iOS程序员 + N名Android程序员 + N名后端程序员可以组成移动开发小组。 N名Unity程序员 + N名后端开发可以组成游戏开发小组。..
更多leetcode刷题笔记(三)
更多leetcode刷题笔记(二)
更多leetcode刷题笔记(一)
======================
更多
【笔记】TCP/IP---链路层
以太网 是当今现有局域网采用的最通用的通信协议标准。以太网络使用CSMA/CD(载波监听多路访问及冲突检测)技术,并以10M/S的速率(仅指标准以太网的速率而已)运行在多种类型的电缆上。以太网与IEEE802.3系列标准相类似 数据封装 上一篇笔记有讲到过封装,数据封装过程是由应用程序开始发送数据,经过传输层和网络层并被封装最后到数据链路层封装后转换成比特流。 封装格式 最常用的封装格式为RFC 894(以太网的封装格式)。下图是RFC 894与另外一种封装格式RFC 1042(IEEE802.2/802.3)的区别 目的地址:也就是网卡的硬件地址,6个字节,指明帧的接受者 源M地址:网卡的硬件地址,6个字节,指明帧的发送者 长度:2个字节,指明该帧数据字段的长度,但不代表数据字段长度能够达到(2^16..
更多
【笔记】TCP/IP---IP:网际协议
简介 IP是TCP/IP协议族中最核心的协议。所有的TCP、UDP、ICMP和IGMP数据都以IP数据报格式传输。IP也决定了接收到的数据将被分发到哪个网络进程。 IP地址 IP地址(Internet Protocol Address),缩写为IP Adress,是一种在Internet上的给主机统一编址的地址格式,也称为网络协议(IP协议)地址。它为互联网上的每一个网络和每一台主机分配一个逻辑地址,常见的IP地址,分为IPv4与IPv6两大类,当前广泛应用的是IPv4,目前IPv4几乎耗尽IPv6号称可以为世界上每一粒沙子都编上地址;如无特别注明,一般讲的的IP地址所指的是IPv4。 MAC地址 MAC(Media Access Control,介质访问控制)地址,或称为物理地址,也叫硬件地址,用来定义网..
更多
【笔记】TCP/IP---简介
分层 网络协议通常分为不同的层次进行开发,每一层分别负责不同分通信功能。 TCP/IP协议族分为四层 链路层: 与硬件相关,通常用来处理计算机中的网卡,设备驱动等。 ####运输层: 有两个不同的传输协议— TCP(传输控制协议) 和 UDP(用户数据报协议)。 平时开发中与数据库交互的接口用到的就是运输层 ####网络层: 处理分组在网络中的活动。IP协议,ICMP协议都是网络层。IP协议不可靠,传输不稳定,不一定能接收到而且可能是无序的。 ####应用层: 任何TCP/IP都会实现这些应用程序,相当于是捆绑在TCP/IP上的程序 Telnet远程登录 FTP文件传输协议 SMTP简单邮件传输协议 SNMP简单网络管理协议 一个局域网内有两台主机,都运行ftp协议。其中涉及到哪些网络层? 图中是一..
更多
Python爬虫之Scrapy-框架原理
Scrapy介绍 scrapy框架包含以下几个部分 Scrapy Engine 引擎 Spiders 爬虫 Scheduler 调度器 Downloader 下载器 Item Pipeline 项目管道 Downloader Middlewares 下载器中间件 Spider Middlewares 爬虫中间件 框架中有那么多部分组成,那每个部件都是用来做什么的?查阅官方文档后我有了以下结论 Scrapy Engine引擎 它是负责整个框架中信号,数据等传递功能。相当于是军队中的主公,任何事情必须经过它的手由它来决定这件事情由谁来负责。 Spiders爬虫 是这个框架中的军师,负责处理所有的Response,返回封装在Item中的数据包。如果有更深层的URL,它将返回给Scrapy Engine,再次..
更多Python爬虫之Scrapy-安装及入门
简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 ###环境需求 Python2.7 或者Python3.5以上 安装 在安装前需要确定当前的Python是什么版本,否则会出现环境变量与当前版本不匹配的情况导致找不到文件:command not found pip install scrapy 如果安装太慢,就把镜像源改为国内: pip install -i https://pypi.douban.com/simple scrapy 安装过程中你会发现,scrapy有大量的依赖库: twisted 基于事件驱动和异步的网络框架 lxml python的一个解析库,支持HTML和XML的解析,支持XPath解..
更多Python数据分析之Pandas-matplotlib基础功能(二)
使用pandas和seaborn绘图 Series和DataFrame自带的生成图表方法: import pandas as pd s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10)) s.plot() 使用pandas做一张堆积柱状图 展示每天各种聚会规模的数据点的百分比 tips = pd.read_csv('examples/tips.csv') party_counts = pd.crosstab(tips['day'], tips['size']) print(party_counts) size 1 2 3 4 5 6 day Fri ..
更多Python数据分析之Pandas-matplotlib基础功能(一)
matplot API入门 如何引入: import matplotlib.pyplot as plt 一个简单的例子: import numpy as np data = np.arange(10) plt.plot(data) print(data) [0 1 2 3 4 5 6 7 8 9] 效果如下: Figure和Subplot matplot的图像都位于Fugure对象中,相当于一个画板,如何创建Figure对象。 fig = plt.figure() ax1 = fig.add_subplot(2, 2, 1) ax2 = fig.add_subplot(2, 2, 2) ax3 = fig.add_subplot(2, 2, 3) 想要实现绘图,必须先使用add_subplot..
更多
实战项目练习-【2018世界杯】用Python分析夺冠球队
前言 在网上找到了个用Python分析2018世界杯夺冠热门的项目,感觉很有意思准备拿来练练手。 因为目前还没有学到图形可视化部分,所以这部分内容会完全借鉴网上的教程。 分析目的 通过数据分析找出哪些队伍是这次世界杯的夺冠热门球队 开发环境 Python 3.7 SublimeText2 初步分析数据情况 import numpy as np import pandas as pd import matplotlib.pyplot as plt from pandas import DataFrame,Series df = pd.read_csv('results.csv') print(df.head()) 由于sublimetext上打印数据显示不全,所以打印数据放在ipython中了 I..
更多实战项目练习-链家二手房数据(清洗与合并)
前言 现在已经学到了数据规整与合并这一章,为了加深对数据分析的理解接下来需要做个小项目练习一下。 目的 通过项目能够真实的了解到数据分析是做什么的 加深对pandas的熟悉程度 重新梳理一下目前学到的那些基础知识,查缺补漏 前期准备 此次项目准备对2018年北京链家网的二手房数据做一次分析 数据来源:Python数据科学的公众号 工具:暂时还是使用iTerm2,还未找到更合适的开发工具。Sublime Text2目前也在用,这次项目小不打算用这个。 导入数据文件并进行初步观察 这些观察包括了解数据特征的缺失值,异常值,以及大概的描述性统计。 In [10]: lianjia_df = pd.read_csv('lianjia/lianjia.csv') # 先查看前5行数据 In [11]: lian..
更多
Python数据分析之Pandas-过滤与清理
移除重复数据 DataFrame中常常会出现重复行。如下面这个例子: In [295]: data = DataFrame({'k1':['one']*3 + ['two'] * 4, 'k2':[1,1,2,3,3,4,4]}) In [296]: data Out[296]: k1 k2 0 one 1 1 one 1 2 one 2 3 two 3 4 two 3 5 two 4 6 two 4 DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行: In [297]: data.duplicated() Out[297]: 0 False 1 True 2 Fals..
更多Python数据分析之Pandas-重塑
重塑层次化索引 层次化索引为DataFrame数据的重排任务提供了一种良好一致性的方式。主要功能: stack: 将数据的列”旋转“为行 unstack:将数据的行“旋转”为列 接下来看一个行列索引均为字符串的例子: In [169]: data = DataFrame(np.arange(6).reshape((2,3)),index=pd.Index(['Ohio','Colorado'],name='sta ...: te'),columns=pd.Index(['one','two','three'],name='number')) In [170]: data Out[170]: number one two three state Ohio 0 1..
更多Python数据分析之Pandas-聚合与合并(二)
索引上的合并 **比如DataFrame中连接键位于其索引中的情况,传入left_index=True或right_index=True以说明索引应该被用作连接键: In [62]: left1 = DataFrame({'key':['a','b','a','a','b','c'],'value':range(6)}) In [63]: right1 = DataFrame({'group_val':[3.5, 7]}, index=['a','b']) In [64]: left1 Out[64]: key value 0 a 0 1 b 1 2 a 2 3 a 3 4 b 4 5 ..
更多Python数据分析之Pandas-聚合与合并(一)
层次化索引 层次化索引让你能在一个轴上拥有多个索引级别。 层次化索引我个人理解是对索引进行了分组,比方说一部分数据是今年的,一部分数据是明年的,可通过层次化索引进行切块以方便后续选取数据 In [263]: data = Series(np.random.randn(10), index=[['2010','2010','2010','2011','2011','2011','2012','2012','2013','2013'],[ ...: 1, 2, 3, 1, 2, 3, 1, 2, 2, 3]]) # 这种形式叫做带有```MultiIndex```索引的格式化输出形式。 In [264]: data Out[264]: 2010 1 1.739760 2 ..
更多
Python数据分析之Pandas-数据清理
合并数据集 离散化和面元划分 为了方便分析,连续数据常常被离散化或拆分为“面元”,可以看下面的例子: ages = [20,22,25,27,21,23,37,31,61,55,29] 可以看到上面这组表示年龄的数据非常的杂乱无序,接下来需要用到cat函数来对它们进行分割 In [90]: bins = [18, 25, 35, 60, 100] In [91]: cats = pd.cut(ages, bins) ca In [92]: cats Out[92]: [(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (35, 60], (25, 35], (60, 100], (35, 60], (25, 35]] Length: 11 ..
更多
Python数据分析之Pandas-数据文件加载与存储(二)
读取Microsoft Excel文件 Excel作为最典型的表格型数据,我们需要用到ExcelFile对象,首先需要下载安装xlrd和openpyxl包 In [11]: xls_file = pd.ExcelFile('ex1.xlsx') In [12]: table = xls_file.parse('Sheet1') In [13]: table Out[13]: Unnamed: 0 a b c d message 0 0 1 2 3 4 hello 1 1 5 6 7 8 world 2 2 9 10 11 12 foo 用requests与Web AP..
更多Python数据分析之Pandas-数据文件加载与存储(一)
读写文本格式的数据 通过cat 输出文件内容: In [20]: cat ex1.csv a,b,c,d,message 1,2,3,4,hello 5,6,7,8,world 9,10,11,12,foo 由于文件是csv格式,可以使用read_csv读取文件并返回DataFrame: In [23]: df = pd.read_csv('ex1.csv') In [24]: df Out[24]: a b c d message 0 1 2 3 4 hello 1 5 6 7 8 world 2 9 10 11 12 foo 如果想读取没有标题行的文件: In [26]: cat ex2.csv 1,2,3,4,hello 5..
更多
Python数据分析之Pandas-Series与DataFrame基本功能(五)
层次化索引 层次化索引让你能在一个轴上拥有多个索引级别。 层次化索引我个人理解是对索引进行了分组,比方说一部分数据是今年的,一部分数据是明年的,可通过层次化索引进行切块以方便后续选取数据 In [263]: data = Series(np.random.randn(10), index=[['2010','2010','2010','2011','2011','2011','2012','2012','2013','2013'],[ ...: 1, 2, 3, 1, 2, 3, 1, 2, 2, 3]]) # 这种形式叫做带有```MultiIndex```索引的格式化输出形式。 In [264]: data Out[264]: 2010 1 1.739760 2 ..
更多Python数据分析之Pandas-Series与DataFrame基本功能(三)
汇总和计算描述统计 pandas中有一些常用的统计方法,主要功能是做约简和汇总统计。 In [188]: df = DataFrame([[1.4, np.nan], [7.1, -4.5], [np.nan, np.nan], [0.74, -1.3]], index=['a','b','c','d'], columns=['one','two']) In [190]: df Out[190]: one two a 1.40 NaN b 7.10 -4.5 c NaN NaN d 0.74 -1.3 In [189]: df.sum() Out[189]: one 9.24 two -5.80 dtype: float64 也可以逐列运算: In [191]: d..
更多Python数据分析之Pandas-Series与DataFrame基本功能(四)
如何处理缺失数据 在练习中经常遇到pandas使用浮点值NaN来表示数组中的缺失数据。那我们该如何处理这些缺失数据? In [228]: string_data = Series(['aardvark', 'artichoke', np.nan, 'avocado']) In [229]: string_data Out[229]: 0 aardvark 1 artichoke 2 NaN 3 avocado dtype: object In [230]: string_data.isnull() Out[230]: 0 False 1 False 2 True 3 False dtype: bool 通过isnull函数我们得知了..
更多Python数据分析之Pandas-Series与DataFrame基本功能(二)
算数运算和数据对齐 pandas中的一个功能是对不同索引的对象进行算数运算。在运算时,如果存在不同的索引对,那么结果就是它们的并集。 In [122]: s1 = Series([7.3, -2.5, 3.4, 1.5], index=['a','c','d','e']) In [123]: s2 = Series([-2.1, 3.6, -1.5, 4, 3.1], index=['a','c','e','f','g']) In [124]: s1 Out[124]: a 7.3 c -2.5 d 3.4 e 1.5 dtype: float64 In [125]: s2 Out[125]: a -2.1 c 3.6 e -1.5 f 4.0 g 3..
更多Python数据分析之Pandas-Series与DataFrame基本功能(一)
重新索引 pandas对象的一个重要方法,其作用是创建一个适应新索引的新对象。 reindex在Series上的应用 In [3]: obj = Series([4.5, 7.2, -5.3, 3.6], index=['d','b','a','c']) In [4]: obj Out[4]: d 4.5 b 7.2 a -5.3 c 3.6 dtype: float64 In [5]: obj2 = reindex(['a', 'b', 'c', 'd', 'e']) In [6]: obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e']) In [7]: obj2 Out[7]: a -5.3 b 7.2 c 3.6 d ..
更多Python数据分析之Pandas-Series与DataFrame-
在pandas中接下来要经常用到的数据结构就是Series和DataFrame了。这两个对象为大多数数据处理提供了可靠、易于使用的功能 Series Series是由一组数据以及这组数据所对应的数据标签(即索引)组成。 In [66]: obj = Series([4, 7, -5, 3]) In [67]: obj Out[67]: 0 4 1 7 2 -5 3 3 dtype: int64 其中左边的一列数字即为索引,索引默认是0到N-1的数字。 自定义索引 我们可以通过设置index属性来自定义索引的表现形式。 In [68]: obj2 = Series([4, 7, -5, 3],index = ['d','b','a','c']) In [69]: obj2 O..
更多Python数据分析之Numpy-数组转置与轴对换详解
在数学中,将矩阵的行列互换就称之为转置。那在NumPy数组中也是如此。 NumPy共有三种转置方式**T属性**、transpose方法、swapaxes方法。 T属性 T属性 它比较常用于二维数组,通过行列互换得到一个新的数组,和数学中的转置是一模一样的。 通过转置后得到一个行列互换的新的矩阵: In [170]: arr = np.arange(12).reshape(4,3) In [171]: arr Out[171]: array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]]) In [172]: arr.T Out[172]: array([[ 0, 3, 6, 9]..
更多Python数据分析之Numpy-基本的索引与切片
NumPy数组的切片与Python中列表的区别在于它的切片是直接对原始数据进行操作,也就是说你做的任何修改都会直接影响到源数据,因为它修改的是内存中的数据。 NumPy数组切片与列表切片的区别 In [36]: arr = np.arange(10) In [37]: arr Out[37]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [38]: arr[3:6] Out[38]: array([3, 4, 5]) In [39]: arr[3:6] = 10 In [40]: arr Out[40]: array([ 0, 1, 2, 10, 10, 10, 6, 7, 8, 9]) In [43]: arr2 = arr #将arr赋..
更多Python数据分析之Numpy-ndarray及数据类型
NumPy的ndarray ndarray作为NumPy中最重要的特点,你可以利用这个对数组进行数学运算。 下面来看一个简单的例子 In [1]: import numpy as np In [2]: data = [1, 2, 3, 4, 5] # 创建一个普通的数组 In [3]: data2 = np.array(data) # 通过np.array函数把data转为ndarray对象 In [4]: data2 Out[4]: array([1, 2, 3, 4, 5]) In [5]: data Out[5]: [1, 2, 3, 4, 5] # 粗略一看发现没什么特别大的区别 继续往下看 In [6]: data2 * 10 Out[6]: array([10, 20, 30,..
更多Python数据分析之Numpy---入门安装介绍
NumPy(Numerical Python)是高性能科学计算和数据分析的基础包,主要功能是对N维数组的操作和计算,其计算效率是Python原生包的N倍,在使用Python做数据分析过程中NumPy是我们必不可少的一个工具。 作为一个基础包,功能上远不及pandas来的那么高级(下面会出pandas系列的笔记),但是作为新手入门NumPy还是很值得我们学习一下,为接下来学习pandas打好基础。 准备工作 安装Python环境 如果没有pip环境请参考这篇文章 pip 的简单安装与基本使用 windows 下载NumPy安装包,注意安装包的Python版本和系统版本。例如numpy-1.16.2-cp27-cp27m-manylinux1_x86_64.whl中cp27指的是python2.7版本..
更多
深度解析Python切片
前言 在平时是否会遇到这样的场景,需要分离出 列表(List)中的部分数据。很多初学者都会想到用while循环去取,很显然这么做肯定是不可取的而且违背了Python之禅中的最重要的一条: Beautiful is better than ugly. 设计高效且漂亮的解决方案是每个程序员的必备素质 那这个时候Python切片就是我们的不二之选,Python切片的表达式十分简单,但是如果不彻底理解它的话很容易出错,这也是为什么本人特地专门为此写一篇文章的原因。 Python切片语法表达式 List[start_index : end_index : step] 先简单解释下这个表达式: start_index : 起始索引值,一般默认为0,表示从列表的初始点开始取值。另外,如果step为负数的话则默认..
更多iOS内存管理那些事
================= 前言 今天在网上看到一道蛮有趣的问题,内容是"对于已经会使用ARC的iOS开发者来说还有必要学习手动内存管理吗?" 。换做一年前的我可能会觉得那必须不用学啊,手动管理内存管理太麻烦了而且很容易出错。ARC现在用下来完全能够解决我日常开发中的所有内存管理的问题,而且苹果在WWDC2011上已经强烈推荐开发者使用ARC,为什么不用ARC呢? 直到我有一次使用了第三方组件,当时这个组件是不支持ARC的。有一天在我做新功能的时候突然出现了一个没有任何踪迹的崩溃,经过了1个通宵的排查和网友的帮助最后才得知原来是非ARC和ARC的代码混用出现的问题,后来还是自己重新写了个非ARC的功能才解决了这个问题。 引用计数 每当一个对象被创建的时候它的引用计数为1,为保..
更多对于 iOS10 中 ATS 的理解
WWDC 15 后,对其中有一项新引入的 features 特别在意,那就是苹果将在 2017 年初即将强制实施的一项隐私保护功能 ATS(App Transport Security)。 在 WWDC 16 中也提到了 ATS,当时声明了 ATS 安全功能与 iOS 9 和 OS X 10.11 一同发布,旨在强制性地使用 HTTPS,以保护应用程序可安全地接入服务器。所有提交到 App Store 的应用程序都需要在 2016 年底执行 ATS 协议。 此处更新于 2016 年 12 月 21 日。 收到消息称苹果将延后强制加入 HTTPS 服务,原因各说纷纭就不详细说明了。至于延期到什么时候还未曾有消息。 ATS(NSAppTransportSecurity) It improves pr..
更多
iOS逆向工程之破解Pokemon Go
期待了很久的精灵宝可梦总算发布了,出于对它的热爱特地问朋友借了个美区的Apple ID下下来准备试玩一番。可是万万没想到的是,我大天朝居然被锁区了。 本着迫切想要玩到它的心情,想了片刻。试试看破解吧,把自己的地理位置改到美国去不就行了嘛!其实这是我第一次尝试iOS逆向,其中过程也是各种心酸,尝试过的人都懂的。 前言 这次主要是想讲下重签名的问题,我直接拿了虾神的半成品,就接下去做了后面的部分。其实前面的部分也很简单,就只是利用Method Swizzle对CLLocation类做了重载,修改了地理位置。接下来就是把该类打包成dylib动态库之后重新注入到app中就可以了。 把项目下载下来我们可以看到这么一个类: 接下来我们需要做这么几步 1.对动态库进行签名,编译后把动态文件注入到pokemongo..
更多WWDC15 总结
=========== 前言 好吧,总算盼到了这次的WWDC,自从开始写博客后越来越喜欢关注这些比较前沿的技术动向。果然这次我热血澎湃的泡了杯咖啡穿上了大裤衩坐在电脑前等待着库克的"Good Morning!" 这次发布会总体看下来对于我们这些开发者来说并没有什么颠覆性的改变,库克还穿着去年的那件深蓝色的T恤,Craig还是那么的幽默风趣。其实这次给我印象比较深刻的也就Multitasking和Swift2开源。 Multitasking 刚刚听到这个功能的时候有点没反应过来,在移动设备上做多任务处理是不是有点鸡肋。首先考虑运行的流畅性,在一个设备上同时运行两个程序我想如果使用以前的旧设备的话那肯定会非常卡。然后如果是在手机上做多任务的话,会因为屏幕太小导致操作起来十分不便,还好仅仅支..
更多
学习如何制作一个像Clear的时髦的手势驱动的备忘录app
================================================== 原文链接:https://www.raywenderlich.com/21842/how-to-make-a-gesture-driven-to-do-list-app-part-13 [译]如何制作一个类似Clear支持手势驱动的备忘录App (一) 学习如何制作一个像Clear的时髦的手势驱动的备忘录app 这是由教程组的成员Colin Eberhardt, ShinobiControls的CTO, 一名会打造有趣又强大的iOS控件的开发者。看看他们的app,ShinobiPlay。你还能在Google+ 和 Twitter上找到Colin的踪迹。 这三部分教程将会带你通过开发一个简单的备忘录应用,并且..
更多谈谈Http和Https
=============== 前言 继续上一篇文章深入研究网络相关的知识,因为上一篇还是有很多没有解释很清楚的地方,所以在这里想讲讲自己对http和https的理解。 自从苹果更新了iOS9.0之后一直没机会研究它为什么把所以的请求都改为了https,第一反应肯定是考虑安全方面,那到底http和https有什么区别,https改善了http的哪些安全方面的不足呢? Http的缺点 Http从1990年正式推出到后面更新到Http/2之后就再也没更新。而在安全方面它只是更新到了1.1,也就是说这么多年来Http一直都没有解决安全方面的问题。 1.因为Http的通信是明文的,所以存在被窃听的风险。 2.无法确认身份。 3.无法验证报文的完整性。 通信明文 因为Http本身没有加密功能,所以在通信过程中都是..
更多SDWebImage源码分析
================== ###前言 使用SDWebImage这个第三方开源库也有一段时间了,一直没有机会去深入理解这个库为何如此强大。这次本着冒险的精神花了点时间去里面探索了一番。虽然过程有点痛苦结果也是弄的自己灰头土脸的,不过起码还是有收获的。所以在本blog做一次第一次探险的记录吧。 SDWebImage github地址 原文是这么说的:SDWebImage是一个图片的异步下载器并且支持缓存。 作者是 Konstantinos K.,目前star数已超过1.3w。目前有很多著名的app都在使用这个库,如携程,Facebook等。 虽然它的主要功能就这2点,但是它无可厚非的成为了目前主流的iOS第三方开源库的王者之一。 下面来看一下SDWebImage的类关系图 PS: 图片来自于 ht..
更多
创建自定义UIViewController过渡动画
原文来自Creating Custom UIViewController Transitions Push,pop,cover vertically... 你从iOS中学会了一些漂亮的视图过渡效果,但是如果让你自己制作的话也会很有趣。自定义UIViewController过渡效果能显著地增加用户体验并且让你的app与其他的与众不同。如果你以前没亲自做过自定义过渡,你会发现它的工作量比你预期的要少很多。 在此次课程中,你将会制作一个带有一些自定义UIViewController过渡效果的猜测游戏。当你完成的时候,你将会获得以下技能: Transition的API是怎样的结构 如何使用自定义过渡来实现呈现和消除view controller 如何做有交互的过渡效果 Note: 在此教程中所示的过渡效果是利..
更多细谈iOS8的Self-Sizing Cells
=========================== 之前有篇文章介绍了 FDTemplateLayoutCell,对于UITableViewCell自动计算高度没有做详细的解释,最近用下来感觉自己不能老是依靠第三方控件,这次返回来讲解下iOS8的Working with Self-Sizing Tableview cells 。 对,我要使用Self-Sizing Cells。虽然有点打脸,但身为一个合格的程序员你必须得学会靠自己来解决这些问题,最起码得理解。如果频繁依靠第三方控件我觉得并不是一个优秀程序员该做的事情。 我要使用Self-Sizing Cells 首先有句话要说,这篇文章仅是个人观点,有不同意见的欢迎讨论。 都知道Self-Sizing是iOS8才更新的,最近又做了些调查,发现使用iO..
更多iOS8新特性 UIPresentationController
================================ 先推荐几篇关于UIPresentationController的好文章 iOS8 Presentation Controller Custom presentations using UIPresentationController in Swift 自从iOS8更新之后,swift成为了各个程序员平时议论的焦点,包括我。这几天回顾了下去年的WWDC发现了这次Apple更新了很多好玩的东西,其中我就发现了一个叫UIPresentationController 以前一直都很想做一个比较酷炫的界面过渡效果,但一直没有花时间去研究,这次正好被我机缘巧合的碰到了就顺手拿来研究了一下。 什么是UIPresentationController 其实从..
更多用xctool打包ipa文件自动上传到fir
================================ 准备工作 HomeBrew 环境 在这里就不多介绍了,可以看我写的另外一篇Mac安装记录的文章 安装xctool xctool 如何使用xctool 安装fir fir.im-cli 创建.sh文件(本例用的是sh脚本),如果想用php语言的就创建.php文件。 自动上传fir xctool xctool 是facebook专门对xcode开发的构建工具,在苹果的xcodebuild限制条件种种的环境下很多人都选择了这款工具,并且它是开源的。 如何安装xctool brew update brew install xctool 很方便,这就是为什么要装Homebrew的原因。 下面简单介绍下xctool的命令: 先输入下面的命..
更多配合Autolayou+SizeClasses仿支付宝首页
============================= 准备 在开始之前先简单分析下界面。 首页这个界面总共分为四大部分,最上面是扫一扫和付款码两个按钮,接下来一组按钮,再下面是一个轮播视图,最后是另外一组按钮。 其中有2个难点 1.配合Autolayout实现四等分按钮 2.Scrollview动态修改内部尺寸 这次主要讲的是Autolayout+SizeClasses,能够通过这次练习基本掌握Autolayout配合基本常用控件的特性,所以其他的地方不会讲的很细,而且素材是直接从支付宝8.6.3的ipa中拿的,所以和支付宝还是有些区别的。 实现 第一部分 第一部分其实很简单,其实就是各自的横向坐标位于界面的左半边和右半边的中心,纵向坐标则是与背景底部呈固定距离。 我选择的是把第一部分的背景分割成..
更多讲讲iOS的URL加载系统
============= 前言 最近打算开始做一些进阶训练,所以避免不了要去触碰这些以前想都没想过的东西。现在要做的第一步就是能够比以往更深入的去学习一些知识,这两天花功夫研究了下iOS的URL加载系统,听起来好像很陌生,但是这个东西是我平常用的最多比如SDWebImage,AFNetworking都用到这些知识。 URL加载系统 URL加载系统就是由一套类和协议组成的,这个加载系统的作用就是从URL中加载内容,给服务器上传数据,管理cookies的存储,控制响应数据的缓存以及处理证书的存储和验证等,还可以定制协议扩展。看到这里应该对URL加载系统有一定的了解了吧,知道它到底是干嘛的,在我们平时使用那些涉及到整个系统的控件的时候也知道了它到底做了些什么事情。 接下来再继续深入研究下去,关于上面提到的..
更多使用Autolayout实现动态高度的ScrollView
============================= 前言 自从改用Autolayout作为界面布局的主要核心技术之后一直都没有做这方面的技术总结,最近打算写一系列关于Autolayout的文章,从比较基础的界面到复杂的界面都会去写,就当做是Autolayout的教程吧。 准备 首先你必须得先了解基本的Autolayout的使用方法和特性。 理解ScrollView在Autolayout中的特别之处。 目的 通过Autolayout实现ScrollView的动态布局。 实现简单的动态界面,并且能够让ScrollView在各种设备上正常运行。 步骤简单明确,不需要大量的布局代码。 知道了自己要做什么之后就开始接下来的Autolayout实践过程吧。 实践 首先创建一个支持Size Cla..
更多初探Size Classes笔记
==================== 前言 自从苹果推出了iPhone6和plus,宣布苹果正式进入大屏时代。不单单设计师哭了,连我们这些苦逼的工程师也跟着要一起哭。因为本身iOS不需要和安卓那样考虑自适应的问题,原本这个只有做android的同学才会碰到的问题现在也终于轮到我们iOS开发工程师了。而且相信正在赶项目的同学,听到此消息估计是一口老血喷在屏幕上了。那我们该如何轻松的适配如此多的尺寸呢? 基本概念 查阅了官方文档,苹果给出了这样一个解决方案。 Use size classes to enable a storyboard or xib file to work with all available screen sizes. This enables the user interfac..
更多使用Cocoapods做iOS项目依赖管理
===================== 文档版本更新说明 2015-03-30 初稿v1.0 最近项目积累的越来越多,也开始更加注重提升自己的开发效率,而且平时在做项目的时候越来越发觉得每次导入第三方库尤其浪费时间,所以特地使用pods来管理这些第三方库,好让我在开发时少花些时间在这种没有任何意义的事情上。 CocoaPods简介 CocoaPods项目的源码在Github上管理,所以多多推荐大家使用Github。该项目开始于2011年8月12日,经过多年发展,现在已经成为iOS开发过程中不可缺少的依赖管理标准工具。开发iOS项目不可避免地要使用第三方开源库,CocoaPods的出现使得我们可以节省设置和更新第三方开源库的时间。 CocoaPods的安装和使用介绍 安装方式很简单, 因为Mac下都..
更多UITableViewCell自动计算高度优化
======================= 之前有段时间一直被UITableViewCell的自动计算高度困扰着,查阅过很多资料试过很多种方法,有些勉强能用,有些计算高度不是很稳定会有错误,有些方法太过复杂影响开发效率,再加上苹果的2次发布会推出了2次针对UITableViewCell自动计算高度的改进,但效果都不是很好。所以这次正好有空就在这里统一整理出来,做一次总结,找出我个人觉得目前最好的方法出来。 在这之前我做过一些调查,发现iOS7和iOS6的市场占有比还是有一点的,这个是iOS9发布三周后的数据 发现现在还使用iOS7和iOS6的还是蛮多的,占了10%,所以接下来要做的适配起码要兼容iOS7甚至兼容iOS6。 estimatedRowHeight 这个是在iOS7发布会上推出的一个UITab..
更多使用Cocoapods创建私有库podspec
======================= 前言 最近忽然有种莫名的想自己做点开源项目的想法,再加上自己平时积累的东西越来越多,时候后把这些东西整理出来分享给大家。 之前有写过一篇如何使用Cocoapods的文章,之前查阅过它的文档,发现它还有个更神奇的功能,你可以通过podspec创建自己的私有库,对自己的库进行管理和维护,同时能上传到cocoapods,通过审核后就能使用cocoapods安装自己的库。 如何创建并使用podspec 本文章的前提是已经有git和cocoapods环境的前提下,如果没有可查看这篇文章。 接下来我们要做的有以下几点: 创建私有的 Spec Repo 创建带有pod的工程项目 编辑podspec文件,同时创建pod项目相关的github项目 创建私有的Spec Re..
更多