
前言
在动手学习这块知识之前本身是抱着想了解数据库是如何实现的目的,但越往后越觉得数据库这个项目真的是复杂,但是也十分有趣。所以特地在此记录下我这些天来对sqlite的理解。
本篇文章是以简易版的sqlite(后面简称sqlite)为基础写出来的原理剖析,还有很多sqlite的基本功能还未涉及到,之后我会逐步添加上去。
框架结构
- 本项目用c语言实现
- 测试工具为rspec
本sqlite的基本架构分为:
- 核心层
- 接口
- SQL命令处理程序
- 分词器(Tokenizer)
- 分析器(Parser)
- 代码生成器(Code Generator)
- 虚拟机(后台)
- B树 (B-Tree)
- 页面调度程序(Pager)
- 操作系统接口 (OS Interface)
- 其他辅助类

一般我们把接口和SQL命令处理程序称为前端,把虚拟机称为后端。前端负责处理应用程序传递过来的SQL语句和SQLite命令,对获取的编码分析、优化,并转换为后端能够执行的SQLite内部字节编码。
而后端才是真正的数据库处理工作,对数据的存储,如何做到快速的读写以及减少对磁盘的压力等都是它的工作。
接口(Interface)
在本程序中只有main.c这一个接口,作为sqlite的的程序入口。
分词器(Tokenizer)
当接口程序收到一条SQL语句时要把这个字符串传递给tokenizer。Tokenizer负责把这条SQL语句分割成一个个标识符(token),并把这些标识符传递给解析器。简单来讲就是区分这条语句到底是select还是insert等。
分析器(Parser)
而分析器就负责分词器剩下的工作, 在哪个表操作数据,选取哪些数据,插入到哪个表等。
代码生成器(Code Generater)
分析器解析完成后最终由代码生成器生成虚拟机能看懂的内部代码。如果是更新就传递给虚拟机update,如果是插入就传递给虚拟机insert等。
虚拟机 (Virtual Machine)
虚拟机才是本程序的灵魂啊,它是专为数据库文件操作而存在的引擎。将代码生成器传递过来的代码分配给对应的函数执行相关操作。
B树(B-Tree)
B-Tree是一种专为磁盘等存储设备设计的一种平衡查找树,学过操作系统的同学都知道磁盘的性能开销是十分宝贵的,它的每次IO都很慢很吃性能。而B-Tree这种数据结构能最大程度的优化在查找数据过程中的IO开销,减少查询次数。
页面调度程序(Pager)
B-Tree的每个节点都是按照数据页的形式存储在磁盘中,而Pager则负责读写以及缓存数据页。
OS接口
OS Interface也成为VFS,该模块提供了跨操作系统的可移植性。简单来讲就是能够使sqlite适应在不同的操作系统上。如read()、write()、lseek()等都是OS接口部分。
测试代码
测试脚本,负责对sqlite大部分功能的测试工作。本项目使用的是ruby的rspec测试框架。
分词器
目前只实现了select·insert exit
为分词器设计了一个缓冲区结构InputBuffer
typedef struct InputBuffer {
char* buffer;
size_t buffer_length;
ssize_t input_length;
}InputBuffer;
而分词器的功能就是从输入流中获取一行二进制字符串(对的,目前只能一行一行分)
ssize_t bytes_read = getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
然后将获取到的数据流封装进InputBuffer中传递给解析器Parser
解析器(Parser)
解析器收到分词器的数据后通过strncmp函数进行截取来判断将执行什么操作。对的,只支持插入、查询业务功能。
/*
* 解析器
* SQL Command Processor
*/
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
return prepare_insert(input_buffer, statement);
}
if (strcmp(input_buffer->buffer, "select") == 0) {
statement->type = STATEMENT_SELECT;
return PREPARE_SUCCESS;
}
return PREPARE_UNRECOGNIZED_STATEMENT;
}
其他解析器
MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
} else if (strcmp(input_buffer->buffer, ".btree") == 0) {
printf("Tree:\n");
print_tree(table->pager, 0, 0);
return META_COMMAND_SUCCESS;
} else if (strcmp(input_buffer->buffer, ".constants") == 0) {
printf("Constants:\n");
print_constants();
return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
}
虚拟机
为虚拟机创建了两个类 Pager 、 Table 、Row
typedef struct Pager {
int file_descriptor;
uint32_t file_length;
uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
}Pager;
typedef struct Table {
Pager* pager;
uint32_t root_page_num;
}Table;
struct Row_t {
uint32_t id;
char username[COLUMN_USERNAME_SIZE + 1];
char email[COLUMN_EMAIL_SIZE + 1];
};
typedef struct Row_t Row;
- Pager:这个页面调度程序负责管理所有节点,整个数据表中的节点都存储在
Pager->pages中。 - Table: 表对象充当着BTree的管理,它直接联系着BTree的根节点
root_page_num - Row:: 代表一行数据
OS接口
在设计select与insert之前,先来研究下OS接口部分。
write
write()会把参数buf所指的内存写入count个字节到所指的文件fd内
ssize_t write (int fd, const void * buf, size_t count);
这里也按照了操作系统的分页的内存管理方式,将数据一页一页的写入到指定文件中。
根据分页地址结构规则,一个页码page_num对应着一个偏移量,所以在确定了页码之后还需要确定偏移量

分页的偏移量offset 也是OS部分的工作,在插入之前先移动到文件的读写位置page*PAGE_SIZE
off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
写入数据到指定文件:
ssize_t bytes_written =
write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
在这里我们将每页大小设计为4096bytes,也就是4k。一般x86操作系统默认分页都是4k,当然现在很多架构下的页面分配方式可以自由选择,有2M、4M的都会有。既然我们是做数据库,本身用到的数据单位不会很大,而且是个轻量级的数据库,设计每页为4k也能起到在节约内存的同时减少磁盘IO次数。
read
read()会把参数fd所指的文件传送count 个字节到buf 指针所指的内存中
ssize_t read(int fd, void * buf, size_t count);
同样读取数据也是按页读取
ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
BTree部分
为什么数据结构部分用的是BTree?
数据库设计这样的数据结构是为了让系统在查询数据的时候最大限度的减少磁盘的IO使用次数,因为数据库中那么多条数据,系统并不知道我们要查询的数据存在哪里,只能一页一页数据的找(系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么)。但是每找一页就是一次的IO,所以为了减少开销,必须在设计数据结构的时候能减少这方面的消耗。
B 树就是常说的“B 减树(B- 树)”,又名平衡多路(即不止两个子树)查找树,它和平衡二叉树的不同有这么几点:
- 平衡二叉树节点最多有两个子树,而 B 树每个节点可以有多个子树,M 阶 B 树表示该树每个节点最多有 M 个子树
- 平衡二叉树每个节点只有一个数据和两个指向孩子的指针,而 B 树每个中间节点有 k-1 个关键字(可以理解为数据)和 k 个子树( k 介于阶数 M 和 M/2 之间,M/2 向上取整)
- B 树的所有叶子节点都在同一层,并且叶子节点只有关键字,指向孩子的指针为 null
和平衡二叉树相同的点在于:B 树的节点数据大小也是按照左小右大,子树与节点的大小比较决定了子树指针所处位置。

BTree中的每个节点对应一个磁盘块(页),上图是一个3阶BTree,每个节点最多有两个关键字和三个指向对应子节点的指针,关键字超过两个就会产生新的子节点。如果我们要查找28这条数据,数据库首先从磁盘中读取磁盘块1,对磁盘块1中的数据进行二分查找,如果不存在就找到目标所在的范围: 17 < 28 < 35 ,然后读取磁盘块3,以此类推最终在磁盘块8中找到了我们要查找的数据,磁盘IO次数为3也就是BTree的阶数。
下图是在网上找的一个4阶BTree的插入数据过程:

BTree实现
叶节点结构:
一个叶节点我们可以显式的定义为有键值,存储子节点地址的指针,数据。但是在内存当中它还有其他元素。
- 键的大小
- 键的位置
- 值的大小
- 值的位置
- 数据大小
- 数据位置
- 子节点大小
- 整个节点的大小
等等。
/*
* 叶节点主体的内存布局
* LEAF_NODE_KEY_SIZE 键大小
* LEAF_NODE_KEY_OFFSET 键的位置
* LEAF_NODE_VALUE_SIZE 值的大小
* LEAF_NODE_VALUE_OFFSET 值的位置
* LEAF_NODE_CELL_SIZE 该字段数据大小
* LEAF_NODE_SPACE_FOR_CELLS 整个叶节点的大小
* LEAF_NODE_MAX_CELLS 该页/节点能存放多少数据
* LEAF_NODE_RIGHT_SPLIT_COUNT 将整个节点一分为2,此为右半部分的数据量
* LEAF_NODE_LEFT_SPLIT_COUNT 此为左半部分的数据量
*/
const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
const uint32_t LEAF_NODE_KEY_OFFSET = 0;
const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
const uint32_t LEAF_NODE_VALUE_OFFSET =
LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
const uint32_t LEAF_NODE_MAX_CELLS =
LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
const uint32_t LEAF_NODE_RIGHT_SPLIT_COUNT = (LEAF_NODE_MAX_CELLS + 1) / 2;
const uint32_t LEAF_NODE_LEFT_SPLIT_COUNT = (LEAF_NODE_MAX_CELLS + 1) - LEAF_NODE_RIGHT_SPLIT_COUNT;
这些都是我们在实现BTree部分时需要用到的常量。
先上一张BTree的插入数据逻辑图:
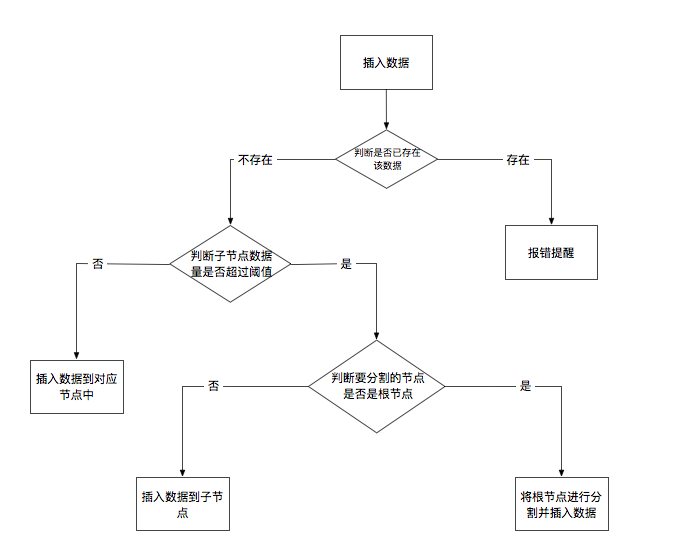
判断是否已存在该数据
if (cursor->cell_num < num_cells) {
uint32_t key_at_index = *leaf_node_key(node, cursor->cell_num);
if (key_at_index == key_to_insert) {
return EXECUTE_DUPLICATE_KEY;
}
}
插入数据到子节点中
/*
创建一个新的节点, 插入新数据到对应的节点中然后更新父节点。
*/
void* old_node = get_page(cursor->table->pager, cursor->page_num);
uint32_t old_max = get_node_max_key(old_node);
uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
void* new_node = get_page(cursor->table->pager, new_page_num);
initialize_leaf_node(new_node);
*node_parent(new_node) = *node_parent(old_node);
*leaf_node_next_leaf(new_node) = *leaf_node_next_leaf(old_node);
*leaf_node_next_leaf(old_node) = new_page_num;
调整位置并存储到内存中
for (int32_t i = LEAF_NODE_MAX_CELLS; i >= 0; i--) {
void* destination_node;
if (i >= LEAF_NODE_LEFT_SPLIT_COUNT) {
destination_node = new_node;
} else {
destination_node = old_node;
}
uint32_t index_within_node = i % LEAF_NODE_LEFT_SPLIT_COUNT;
void* destination = leaf_node_cell(destination_node, index_within_node);
if (i == cursor->cell_num) {
serialize_row(value, leaf_node_value(destination_node, index_within_node));
*leaf_node_key(destination_node, index_within_node) = key;
} else if (i > cursor->cell_num) {
memcpy(destination, leaf_node_cell(old_node, i - 1), LEAF_NODE_CELL_SIZE);
} else {
memcpy(destination, leaf_node_cell(old_node, i), LEAF_NODE_CELL_SIZE);
}
}
如果需要存放到根节点而根节点将超出阈值则需要拆分根节点
/*
* 创建新的根节点
*/
void create_new_root(Table*table, uint32_t right_child_page_num){
/*
* 分割旧的根节点,为旧节点创建新的page变为左子节点,剩余部分变为右子节点
* 重新生成一个带有左右子树的新节点
*
*/
void* root = get_page(table->pager, table->root_page_num);
void* right_child = get_page(table->pager, right_child_page_num);
uint32_t left_child_page_num = get_unused_page_num(table->pager);
void* left_child = get_page(table->pager, left_child_page_num);
/*为旧节点创建新的page变为左子节点*/
memcpy(left_child, root, PAGE_SIZE);
set_node_root(left_child, false);
/*
* 初始化为内部节点
*/
initialize_internal_node(root);
set_node_root(root, true);
*internal_node_num_keys(root) = 1;
*internal_node_child(root, 0) = left_child_page_num;
uint32_t left_child_max_key = get_node_max_key(left_child);
*internal_node_key(root, 0) = left_child_max_key;
*internal_node_right_child(root) = right_child_page_num;
*node_parent(left_child) = table->root_page_num;
*node_parent(right_child) = table->root_page_num;
}
测试部分
测试框架用的是rspec
配置测试环境
配置ruby环境,需要先安装好Ruby(Mac自带Ruby环境)
没有的可以自行安装
先安装rvm
$ curl -L https://raw.githubusercontent.com/wayneeseguin/rvm/master/binscripts/rvm-installer | bash -s stable
再安装ruby
$ rvm install 2.3.0
最后安装bundler
$ gem install bundler
配置依赖文件
配置rspec需要一些依赖文件,因为依赖文件很多,版本也很难单独管理。所以这里我们使Gemfile文件来管理这些依赖。
Gemfile
Gemfile 是我们创建的一个用于描述 gem 之间依赖的文件。gem 是一堆 Ruby 代码的集合,它能够为我们提供调用。你的 Gemfile 必须放在项目的根目录下面, 这是 Bundler 的要求,对于任何的其他形式的包管理文件来说,这也是标准。这里值得注意的一点是 Gemfile 会被作为 Ruby 代码来执行。当在 Bundler 上下文环境中被执行的时能使我们访问一些方法,我们用这些方法来解释 gem 之间的 require 关系。
在Gemfile文件中加入下面几行:
group :development, :test do
gem 'rspec-rails', '~> 3.4'
end
执行bundle install
到这里测试环境就配置好了
执行测试
it 'allows printing out the structure of a 4-leaf-node btree' do
script = [
"insert 18 user18 person18@example.com",
"insert 7 user7 person7@example.com",
"insert 10 user10 person10@example.com",
"insert 29 user29 person29@example.com",
"insert 23 user23 person23@example.com",
"insert 4 user4 person4@example.com",
"insert 14 user14 person14@example.com",
"insert 30 user30 person30@example.com",
"insert 15 user15 person15@example.com",
"insert 26 user26 person26@example.com",
"insert 22 user22 person22@example.com",
"insert 19 user19 person19@example.com",
"insert 2 user2 person2@example.com",
"insert 1 user1 person1@example.com",
"insert 21 user21 person21@example.com",
"insert 11 user11 person11@example.com",
"insert 6 user6 person6@example.com",
"insert 20 user20 person20@example.com",
"insert 5 user5 person5@example.com",
"insert 8 user8 person8@example.com",
"insert 9 user9 person9@example.com",
"insert 3 user3 person3@example.com",
"insert 12 user12 person12@example.com",
"insert 27 user27 person27@example.com",
"insert 17 user17 person17@example.com",
"insert 16 user16 person16@example.com",
"insert 13 user13 person13@example.com",
"insert 24 user24 person24@example.com",
"insert 25 user25 person25@example.com",
"insert 28 user28 person28@example.com",
".btree",
".exit",
]
result = run_script(script)
expect(result[30...(result.length)]).to eq([
"db > Tree:",
"- internal (size 3)",
" - leaf (size 7)",
" - 1",
" - 2",
" - 3",
" - 4",
" - 5",
" - 6",
" - 7",
" - key 7",
" - leaf (size 8)",
" - 8",
" - 9",
" - 10",
" - 11",
" - 12",
" - 13",
" - 14",
" - 15",
" - key 15",
" - leaf (size 7)",
" - 16",
" - 17",
" - 18",
" - 19",
" - 20",
" - 21",
" - 22",
" - key 22",
" - leaf (size 8)",
" - 23",
" - 24",
" - 25",
" - 26",
" - 27",
" - 28",
" - 29",
" - 30",
"db > ",
])
end
写完测试脚本后执行测试
bundle exec rspec
bundle exec rspec
............
Finished in 0.37043 seconds (files took 0.55291 seconds to load)
12 examples, 0 failures
数据库是一个很庞大的系统,我现在只是实现了其中的凤毛麟角,接下来我有时间会继续实现未完成的部分。
下一篇文章会加入删除、更新部分等常用数据库功能。
参考文献
《Inside Sqlite》
《sqlite database system: design and implementation》