最近在学C++,在刷题的时候遇到了关于引用、指针的问题,重温相关知识后发现C++中的引用于python中引用有很大的区别,我想这就是C++效率远高于python的原因之一。通过两篇文章想梳理下python与C++在引用上的区别以及C++中引用和指针的区别。
Python的引用
在python中引用就是引用赋值,等同于浅拷贝,可以看一个例子:
In [13]: a = 1
In [14]: b = a
In [15]: id(a)
Out[15]: 4553065616
In [16]: id(b)
Out[16]: 4553065616
In [20]: b is a
Out[20]: True
In [21]: b == a
Out[21]: True
上面代码中先初始化了一个值为1,名字为a的变量(其实python没有变量,正确说法是标签),因为它无需声明变量类型,之后变量b引用了标签a,这个时候标签b的值等同于标签a的值并且它们的内存地址也是相同的。
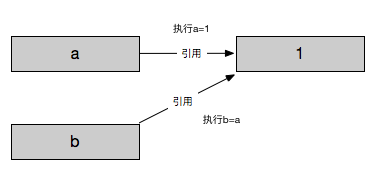
但是python中引用还有另外一个特性:可以对应用进行更改
In [23]: b = 2
In [24]: id(b)
Out[24]: 4553065648
In [25]: a
Out[25]: 1
In [26]: id(a)
Out[26]: 4553065616
---------------------
In [24]: b=b+1
In [25]: b
Out[25]: 2
In [26]: a
Out[26]: 1
In [27]: id(a)
Out[27]: 4369581200
In [28]: id(b)
Out[28]: 4369581232
这个时候变量b已经不再引用变量a了,而是引用了2这么一个int数据,并且它的内存地址也不再与a相同。再回过头来看a,发现a并没有被b给影响到。这里其实要细说的话可以归功于在python中int数据类型是不可变数据类型,所以在变量b被重新引用后没有将a的值以及内存做改变,也就是说int是一个线程安全的数据类型。
PS
python在引用上与C++最大的区别就是:C++的引用一旦被赋值之后将不能改变引用对象,接下来的赋值操作都只会修改引用对象本身。
而python不一样,它没有这个概念,引用被赋值后它会把标签挂到最新的对象上。
可变类型数据
接下来再看下python中对于可变类型数据的引用是怎么样的
In [1]: a = [1,2,3]
In [2]: b = a
In [4]: b.append(4)
In [5]: b
Out[5]: [1, 2, 3, 4]
In [6]: id(b)
Out[6]: 4415640192
In [7]: id(a)
Out[7]: 4415640192
In [8]: a
Out[8]: [1, 2, 3, 4]
对于可变类型数据,标签b先引用了标签a所引用的对象。这个时候我们去操作标签b对数据进行更改,会发现标签a所引用的对象也受到了改变。
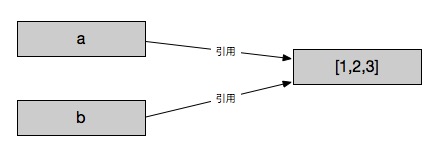
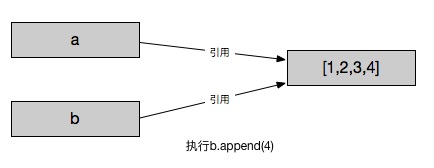
在对可变类型数据执行更改操作的时候,它们操作的本身其实就是引用的对象。所以不管是a还是b做了更改操作都会影响到该对象的其他引用。
如果对可变类型数据做重新赋值操作
In [12]: a=[1,2,3]
In [13]: b=a
In [14]: b=[2,3,4]
In [15]: a
Out[15]: [1, 2, 3]
In [16]: id(a)
Out[16]: 4406584576
In [17]: id(b)
Out[17]: 4406530608
这个时候就又会回到和不可变类型一样的情况了,标签b去重新引用了新的对象,和a说拜拜了。
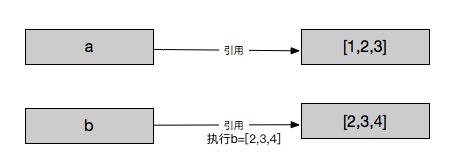
接下来再看一个比较经典的例子
由于可变数据的更改操作其实就是更改它们的引用,会有这种情况出现
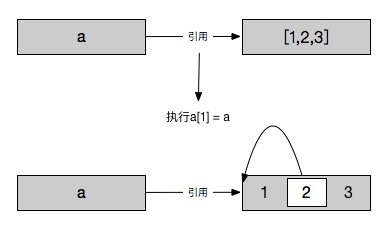
In [37]: a = [1,2,3]
In [38]: a[1] = a
In [39]: a
Out[39]: [1, [...], 3]
我把a[1]做了更改操作,使其指向了标签a引用的对象。本以为结果是[1,[1,2,3],3],由于更改操作只会修改引用对象本身, 列表[1,?,3]中的?指向了a本身从而导致了循环
要避免这种情况可以通过复制来解决这个问题。
In [41]: a = [1,2,3]
In [42]: a[1] = copy.copy(a)
In [43]: a
Out[43]: [1, [1, 2, 3], 3]
浅拷贝
对于不可变类型,浅拷贝与赋值没有区别
In [49]: a=1
In [50]: b = copy.copy(a)
In [51]: b
Out[51]: 1
In [52]: id(a)
Out[52]: 4369581200
In [53]: id(b)
Out[53]: 4369581200
标签b与标签a都将指向该数据。
再来看上面那道造成循环的题,在这儿我们可以通过拷贝来解决。
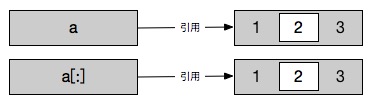
In [1]: a = [1,2,3]
In [2]: a[1] = a[:]
In [3]: a
Out[3]: [1, [1, 2, 3], 3]
在这里我们用切片作为拷贝操作,随后将a引用的对象中的第二个元素指向我们复制来的新对象。
浅拷贝的缺陷
某天无意中发现了一个浅拷贝的缺点,很有意思。
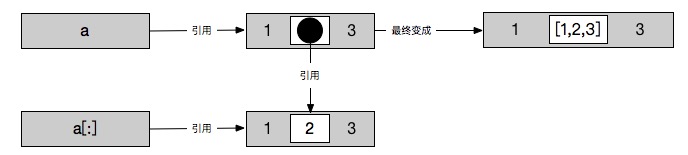
In [31]: a=[1,[2,3],4]
In [32]: b=a[:]
In [33]: id(a[1])
Out[33]: 4436979376
In [34]: id(b[1])
Out[34]: 4436979376
In [40]: a[1][1] = 2
In [41]: a
Out[41]: [1, [2, 2], 4]
In [42]: b
Out[42]: [1, [2, 2], 4]
前面我们总结了如果浅拷贝可变数据的话,编译器会重新开辟一块内存来存储新对象,也就是说可变数据拷贝出来的新对象与原对象不是同一个对象。但是在上面例子的情况中,不可变数据作为不可变数据对象的元素存在时,拷贝会将它视作不可变对象来处理,所以我们会看到上面a[1]与b[1]内存地址相同的情况。
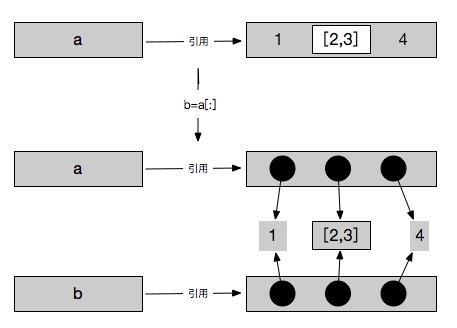
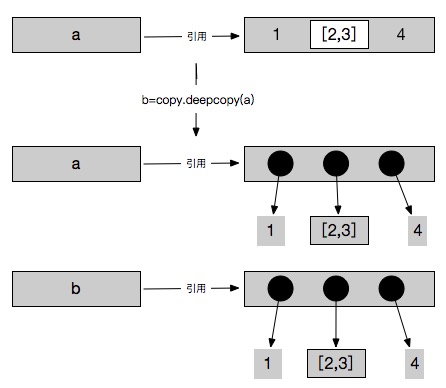
要解决这个问题我们就必须要使用深拷贝了
深拷贝
In [43]: a=[1,[2,3],4]
In [44]: b = copy.deepcopy(a)
In [45]: a[1][1]=2
In [46]: a
Out[46]: [1, [2, 2], 4]
In [47]: b
Out[47]: [1, [2, 3], 4]
通过深拷贝来为嵌套元素开辟新的内存。